What this report is, and how to read it
Most writing about AI search optimization is assertion without mechanism: a list of tactics with no account of why they would work. This report takes the opposite approach. It starts from how these systems actually work, according to the companies that build them, and reasons forward to what that mechanism implies for getting found, consulted, and cited.
That approach sets a strict rule about evidence, and the report holds to it visibly rather than asking you to trust it. Three kinds of claim appear here, and the text marks which is which.
Documented fact
Every claim about how the systems work is sourced to official vendor documentation, read in full. Where this report says Google, OpenAI, or Anthropic states something, it is their own published material, not a third-party rendition of it.
Interpretation
Every optimization lever is reasoning from that documented mechanism, marked as interpretation rather than dressed up as something a vendor said. It is included only where it follows from the mechanism, never where it would require knowing what vendors do not publish.
Field observation
A small number of points come from practitioner work rather than vendor documentation. These are real but not vendor-documented, and the text marks them as such.
The reason for this discipline is not pedantry. The seam between what is known and what is inferred is exactly where weak AI-search advice hides. Making the seam visible is what separates a defensible report from confident guesswork.
The three terms, drawn apart
SEO, AEO, and GEO are used interchangeably across the industry, which is most of why the industry's advice is muddled. This report keeps them distinct on a mechanical basis, developed fully in the levers section. They are best understood as three concentric outcomes.
- SEO is being retrievable and rankable in an index. It is the precondition layer.
- AEO, answer engine optimization, is being the cited source inside an answer, the visible, clickable citation.
- GEO, generative engine optimization, is influencing the generated answer at all, cited or not.
They are concentric, not separate toolkits: you must be retrievable to be consulted, and consulted to be cited. The same content asset can serve all three, which is why the levers later are organized by the mechanism they exploit rather than by the label they serve. Worth noting that Google itself argues optimizing for its generative features is still SEO. That is true for Google's surface and is taken seriously here; it is also not the whole story once ChatGPT and Claude, which retrieve differently, are in scope. Reconciling that is part of the work.
How the report is organized
It moves from mechanism to practice. How language models work covers the minimum mechanics, tokens, embeddings, attention, parametric knowledge, hallucination, knowledge cutoffs, and why those properties make retrieval necessary. How retrieval works establishes the fetch-filter-generate-cite loop all three systems share, the spine of the report. How each surface retrieves and cites covers Google's AI Overviews and AI Mode, the Gemini assistant, ChatGPT Search, and Claude web search in depth, with Perplexity added for what its own documentation supports, where they differ, and the gate to each. The gate before retrieval covers entity recognition, how the model's prior knowledge shapes whether it understands a brand before it searches at all. The levers sets out the optimization moves that follow from the mechanism, each tied to the documented fact it rests on and the outcome it serves. Measuring it honestly covers how to measure each layer, including the dedicated Google Search Console generative-AI report launched in June 2026, and closes with the agenda for turning the framework into proof for a specific brand.
The early sections are mostly fact, building the picture; the later ones turn it into practice. If you want the practical payoff first, read the levers, then come back for the mechanism that justifies them.
Foundations
How Language Models Work
Why a marketer needs the model layer at all
You can run a competent SEO program without knowing how a transformer works. You cannot reason clearly about why generative search behaves the way it does without it, and reasoning clearly is the whole point of this report. The mechanics below are the minimum needed to understand why retrieval exists, why models sometimes state confident falsehoods, and why "the passage, not the page" turns out to be the operative unit. Each concept is introduced for that purpose and no further. This is a working understanding, not a course.
Tokens: text becomes numbers
A language model does not read words. It reads tokens, which are chunks of text, often a word or a fragment of one, each mapped to a number. "Property maintenance" might become three or four tokens. Everything the model does happens over these numeric tokens, and everything it produces is generated one token at a time.
Why it matters. The model's whole world is sequences of tokens and the statistical relationships between them. There is no separate store of "facts" sitting behind the words; the knowledge is encoded in the relationships. That is the root of why models can be fluent and wrong at once, which the rest of this part builds toward.
Embeddings: meaning becomes geometry
Each token is represented as a vector, a long list of numbers, called an embedding. The useful property is that these vectors encode meaning as position in space: tokens and passages with similar meanings sit near each other, and dissimilar ones sit far apart. "Landlord" and "property manager" land in a similar neighborhood; "landlord" and "photosynthesis" do not.
Why it matters. This is the mechanical basis of retrieval, which the retrieval section depends on. When a generative search system "finds relevant passages," it is in large part comparing embeddings: turning the query into a vector and pulling content whose vectors sit nearby. Relevance, in this world, is geometric proximity in meaning-space. It is why a page can be retrieved for a query that shares no exact keywords with it, and why Google can say its systems understand relevance even with no exact match between query and page.
Attention and generation: predicting the next token in context
The transformer architecture that underlies modern LLMs works, at its core, through a mechanism called attention: when processing each token, the model weighs how much every other token in the context should influence it. This lets it handle context and long-range relationships rather than treating words in isolation. From that weighted understanding of the context so far, the model predicts the next token, appends it, and repeats. An answer is built one token at a time, each conditioned on everything before it.
Why it matters. Two things follow. First, the model is a prediction engine over context, not a database lookup, so what sits in its context window at generation time heavily shapes the output. This is exactly the lever retrieval pulls: put the right retrieved passages in context and the prediction is grounded in them. Second, because generation is probabilistic next-token prediction, the model will produce fluent, plausible continuations whether or not they are true, which leads directly to the next point.
Parametric knowledge and why models hallucinate
During training, the model adjusts billions of internal parameters to capture statistical patterns across its training data. The knowledge it retains this way is called parametric knowledge: it is baked into the weights, not stored as retrievable records. When you ask a question without giving the model a way to look anything up, it answers from this parametric knowledge by predicting the most plausible continuation.
The failure mode this creates is hallucination: a confident, fluent statement that is false. It happens because the model is optimizing for plausible continuation, not for truth, and it has no built-in way to check a claim against a source unless it is given one. A citation produced from parametric memory alone can be a well-formed reference to something that does not exist, because the model has learned what citations look like, not whether this particular one is real.
Why it matters. This is the entire reason retrieval-augmented generation exists, and therefore the reason this report exists. If models could be trusted to answer accurately from parametric knowledge alone, there would be no retrieval step, no citations, and no visibility game to play. Hallucination and staleness are the problems; grounding in retrieved content is the industry's answer; and that answer is precisely what creates the opportunity to be the content that gets retrieved and cited.
Knowledge cutoffs and the case for retrieval
Parametric knowledge is frozen at the point training data was collected, the knowledge cutoff. Anything after it, and anything too niche or fast-changing to be reliably captured, is outside what the model knows on its own. This is not a bug to be patched; it is structural, because retraining a frontier model is expensive and infrequent relative to how fast the world changes.
Why it matters, and the bridge to retrieval. A frozen, sometimes-wrong knowledge store that nonetheless speaks fluently is a problem with an obvious shape of solution: before answering, go fetch current, relevant, verifiable content from outside the model, and ground the answer in it. That is retrieval-augmented generation. Every provider in this report has built some version of it, and every lever later is ultimately about being the content that this retrieval step finds, trusts, and lifts. The next section picks up exactly there.
Mechanism
How Retrieval Works
- Google, "Optimizing your website for generative AI features on Google Search," Search Central (updated 2026-06-05)
- Google, "AI Features and Your Website," Search Central (updated 2025-12-10)
- OpenAI, "Web search," API documentation (developers.openai.com)
- Anthropic, "Web search tool," Claude platform documentation (platform.claude.com)
The one mechanism that matters
Generative search does not rank pages and hand you a list. It fetches information, then writes an answer grounded in what it fetched. Google names this directly: retrieval-augmented generation, also called grounding, is the technique its AI features use to pull relevant pages from the Search index and generate a response from them, with clickable links back to the supporting pages.
Strip the branding off the three major systems and the same four-step shape appears in all of their documentation.
Step 1: One question becomes many queries
None of these systems searches only the words you typed. Google calls its version query fan-out, and documents it as a set of concurrent, related queries the model generates to fetch additional relevant results. The example in Google's own guide is worth keeping because it is concrete: for the query "how to fix a lawn that's full of weeds," the fan-out queries might include "best herbicides for lawns," "remove weeds without chemicals," and "how to prevent weeds in lawn." Google's other documentation adds that both AI Overviews and AI Mode may issue these multiple related searches across subtopics and data sources to develop a response.
OpenAI documents the same expansion as a property of how its search modes work. In agentic search, the model performs web searches as part of its chain of thought, analyzes the results, and decides whether to keep searching. Its deep research mode can tap into hundreds of sources over a single run. Anthropic documents that Claude decides when to search based on the prompt, and that the search process may repeat multiple times throughout a single request before Claude gives its final answer.
Interpretation If a single user question is answered by retrieving against many sub-questions, then content that addresses the cluster of sub-questions around a topic has more surfaces on which to be retrieved than content that answers only the headline query. This is not a license to spin up a page per query variant. Google explicitly warns that creating separate content for every possible search variation, done primarily to manipulate rankings or AI responses, violates its scaled content abuse spam policy. The defensible reading is narrower: cover the genuine sub-questions of a topic within coherent, genuinely useful content, because that is the shape of what gets retrieved against.
Step 2: Retrieval runs on an index you already know
A persistent myth is that AI search reads the live web fresh each time, or reads from some separate "AI index" you optimize for differently. Google's documentation closes this directly. Its generative AI features are rooted in its core Search ranking and quality systems, and RAG relies on those same systems to retrieve pages from the Search index. There is no separate index.
The consequence is stated by Google as a hard gate: to be eligible to appear as a supporting link in AI Overviews or AI Mode, a page must be indexed and eligible to be shown in Google Search with a snippet, and there are no additional technical requirements. Google also keeps the honest caveat that meeting every requirement still does not guarantee crawling, indexing, or serving.
The other two systems retrieve from their own sources rather than Google's index, and they expose controls that reveal how retrieval is scoped. OpenAI's web search tool supports domain filtering, allowing up to 100 allowed or blocked domains per request. Anthropic's web search tool exposes the same kind of control through allowed_domains and blocked_domains parameters. These are developer controls rather than statements about ranking, but they confirm the architecture: a retrieval step happens against a scoped set of sources before the model writes anything.
Interpretation For Google specifically, this collapses a distinction people spend money trying to maintain. If a page cannot rank in classic Search because it is not indexed, is technically broken, or is too thin to earn a snippet, it is not eligible for the AI answer either. Traditional technical SEO is not a separate workstream from AI visibility on Google's surface; it is the precondition for it. Google says as much when it states its AI features are still SEO from its perspective.
Step 3: Retrieved content is filtered for relevance before generation
This is the step most "AEO" advice skips, and it is the one with the clearest documentation. Anthropic is the most explicit. Its current web search tool version performs dynamic filtering: Claude can write and execute code to filter search results before they reach the context window, keeping only relevant information and discarding the rest. Anthropic states the reason plainly: web search is token-intensive, much of the fetched content is irrelevant, and that irrelevant content can degrade response quality. So the system actively discards the parts of a retrieved page that do not bear on the query before composing an answer.
Google describes the same selectivity from the publishing side. In telling site owners they do not need to break content into small pieces, Google says its systems are able to understand the nuance of multiple topics on a page and show the relevant piece to users. The phrase that matters there is "the relevant piece." Google is describing passage-level selection happening on its end. It is not asking you to chunk your content; it is saying it already isolates the relevant passage itself.
OpenAI exposes the same reality through its API surface. It documents a distinction between two things: inline citations, which surface only the most relevant references, and the full sources list, which returns the complete set of URLs the model consulted. OpenAI states directly that the number of sources is often greater than the number of citations.
Interpretation Two consequences follow, and they are the heart of the report. First, the unit that competes is the passage, not the page. The systems isolate a relevant span and reason over it; a page that buries a clear answer inside unfocused prose gives the filter less to extract cleanly. Second, being consulted and being cited are different outcomes. OpenAI documents the gap explicitly. A page can inform the answer without earning a visible citation, which means visibility in generative search is a spectrum, not a binary, and measuring only visible citations undercounts influence. This is the mechanical basis for separating AEO (being the cited source) from GEO (influencing the generated answer at all).
Step 4: Citations are bound to spans, not pages
When these systems cite, they cite a fragment. Anthropic documents that each citation location carries the source url, the title, an encrypted index, and cited_text of up to 150 characters of the cited content. The cited unit is a short span, capped at 150 characters. OpenAI documents that its url_citation annotation carries the URL, the title, and the start and end character indices in the model's response where that source was used. The citation is anchored to a specific character range of the generated text. Google presents citations in its AI features as prominent, clickable links that support the information in the response, displaying, in its words, a wider and more diverse set of helpful links than a classic web search would.
Interpretation Span-level citation rewards content where a discrete, quotable claim sits cleanly in the text and can be lifted without surrounding context to make sense of it. A self-contained sentence that states a fact or figure plainly is easier to bind a citation to than the same point diffused across a paragraph of setup. This reinforces the passage-level conclusion from Step 3 from a different direction: the systems retrieve passages and they cite spans, so the writing unit to optimize is the self-contained, verifiable statement.
What the vendors do not document
Everything above is mechanism the vendors describe. None of them publishes the part everyone actually wants: how retrieved candidates are scored against each other to decide which sources are selected and which get the visible citation. Google describes RAG, fan-out, the indexing gate, and passage selection, but not the ranking function that orders candidates inside the AI answer. OpenAI documents the modes, the source-versus-citation split, and the annotation format, but not how relevance is scored. Anthropic documents that filtering keeps "relevant" content but not how relevance is judged.
This silence is not a gap in the research; it is the boundary of what can be stated as fact. The levers section treats it as exactly that. Where an optimization lever follows necessarily from documented mechanism, it is presented as interpretation. Where a claim would require knowing the undisclosed scoring function, in particular any quantitative claim that a specific change produces a specific lift in citations, it is carried only by first-party measurement, or it is not made.
Surfaces
How Each Surface Retrieves and Cites
The retrieval section established the loop these systems share. This part is about where they differ, because the differences change what wins. A single piece of content faces several different retrieval architectures, and treating "AI search" as one monolith is the mistake that produces generic advice. Google, OpenAI, and Anthropic are covered in depth, Google across both its search surfaces and its Gemini assistant; Perplexity is added for what its own documentation supports. The honest picture is convergence on the skeleton, divergence on the specifics, and a shared refusal to publish the scoring function.
| Google AI Overviews / AI Mode | OpenAI ChatGPT Search | Anthropic Claude | |
|---|---|---|---|
| Substrate | The existing core Search index. No separate "AI index." | Own sources; Enterprise/Edu may share disassociated queries with Bing. | Own web search; decides when to search based on the prompt. |
| Retrieval move | Query fan-out across subtopics and data sources. | Three modes: non-reasoning, agentic, deep research (hundreds of sources). | Decide-retrieve-cite loop; may repeat within one request. |
| Eligibility gate | Indexed and snippet-eligible in classic Search. No extra requirements. | Bing indexability for the enterprise path. | Clean, self-contained passages for span-binding. |
| Citation unit | Prominent clickable links; wider, more diverse set than classic search. | url_citation with URL, title, character range; sources often exceed citations. | cited_text capped at 150 characters; citations always enabled. |
| Freshness signal | RAG grounds in up-to-date pages. | Search supplements the training cutoff. | Results carry a page_age field. |
Google: AI Overviews and AI Mode
The substrate. Google's generative features run on its existing Search index, not a separate one. The eligibility gate is explicit: to appear as a supporting link in AI Overviews or AI Mode, a page must be indexed and eligible to be shown in Google Search with a snippet, with no additional technical requirements.
The retrieval move. Google documents query fan-out: both AI Overviews and AI Mode may issue multiple related searches across subtopics and data sources to develop a response, and while generating, Google's models identify more supporting pages to show a wider, more diverse set of links than classic search.
The two surfaces differ. Google distinguishes them itself. AI Overviews are designed to appear only where they add benefit beyond classic Search and often do not trigger; AI Mode is built for queries needing exploration, reasoning, or complex comparison that previously took multiple searches.
Measurement. As of June 3, 2026, Google offers a dedicated Search Console report isolating impressions within generative AI features (AI Overviews, AI Mode, and Discover generative features), broken down by pages, countries, devices, and dates, while that data also feeds the overall performance report. Google describes the metric as impressions and notes more metrics may come; it is rolling the report out to a subset of sites. (Secondary reporting holds the rollout is UK-first under the UK CMA's requirements; Google's post says only "a subset of websites.")
What Google says you can skip. For its surface specifically, Google states you do not need llms.txt or special machine-readable files, content "chunking," AI-specific rewriting, or special schema.org markup; structured data is not required for AI features though Google still recommends it for rich results in classic Search.
Interpretation Google's surface collapses AI visibility into SEO more than the other two, because there is one index and one eligibility gate. The practical reading: win classic Search first, cover the genuine sub-questions of a topic so fan-out has surfaces to land on, and do not spend effort on AI-specific markup Google has explicitly disclaimed. The single highest-leverage move is the one Google names as mattering most, original non-commodity content, because that is what its quality systems are tuned to reward and what cannot be faked.
OpenAI: ChatGPT Search
The substrate and modes. OpenAI documents three search behaviors: non-reasoning search that passes a query to the tool and returns top results; agentic search where a reasoning model searches as part of its chain of thought and decides whether to keep going; and deep research that can consult hundreds of sources over minutes. For the consumer ChatGPT Search product, OpenAI states that ChatGPT turns the request into one or more search queries, retrieves results, and generates an answer with links to sources. For Enterprise and Edu, OpenAI documents that it may share disassociated search queries with Bing to return web results.
Citation structure. OpenAI documents inline citations carrying a url_citation annotation with the URL, title, and the start and end character indices in the response where the source was used. Distinctly, it exposes a sources field returning the complete list of URLs the model consulted, and states the number of sources is often greater than the number of citations.
Controls. OpenAI's web search tool supports domain filtering (up to 100 allowed or blocked domains) and approximate user-location localization.
Interpretation Two surface-specific consequences. First, the Bing substrate for enterprise means Bing indexability is a precondition for citation there, a different gate than Google's. Second, OpenAI's documented sources-versus-citations gap is the clearest first-party evidence anywhere that being consulted and being cited are different outcomes, which is the mechanical basis for separating GEO from AEO. The deep-research mode also means that for some queries the competition is to be one of many corroborating sources, not the single best result, which rewards consistent presence over singular dominance.
Anthropic: Claude web search
The mechanism. Anthropic documents a three-step loop: Claude decides when to search based on the prompt, the API executes searches and returns results (which may repeat multiple times in one request), and Claude gives a final answer with cited sources. Claude searches for current or changing information and answers directly from prior knowledge for stable facts.
Dynamic filtering. The current tool version lets Claude write and execute code to filter search results before they reach the context window, keeping only relevant information and discarding the rest. Anthropic's stated reason: web search is token-intensive, much fetched content is irrelevant, and that irrelevant content can degrade response quality.
Citation structure. Citations are always enabled; each cited location carries the url, title, an encrypted index, and cited_text of up to 150 characters. Results also carry a page_age field for when a site was last updated.
Interpretation Anthropic's dynamic filtering is the most explicit first-party statement that relevance filtering happens at the passage level before generation, which is the strongest documented support for the "self-contained passage" lever. The 150-character cited_text cap reinforces it from the citation side: the cited unit is a short, liftable span. The page_age field is documented evidence that freshness is tracked.
Gemini: the assistant, distinct from Google's search surfaces
Google's AI Overviews and AI Mode, covered above, are search surfaces inside Google Search. Gemini is the standalone assistant, a different product, and it grounds differently enough to treat separately. Conflating the two is a common error.
What Google documents. When Gemini grounds an answer in Google Search, Google's Gemini API documentation describes a loop that maps closely onto the others: the model analyzes the prompt and determines whether a Google Search would improve the answer; if so, it generates one or more search queries and executes them; it processes and synthesizes the results; and it returns a grounded response. Google documents that the model does not necessarily search for every prompt, generating queries only when it determines a search would help, which parallels the search-or-answer decision Anthropic documents for Claude. The grounded response carries a groundingMetadata field containing the search queries used, the web results, and the citation data.
Citations are span-level. Google's Gemini API documentation states that a grounded response returns structured citation data in two fields: groundingChunks, an array of web sources (each with a uri and title), and groundingSupports, which connects segments of the model's text to those sources. Each support links a text segment, defined by a start and end index, to one or more source chunks. This is the same passage-to-source binding seen on the other surfaces, and it reinforces the report's central point that the cited unit is a segment of text, not a whole page.
Interpretation Gemini grounded in Google Search is, mechanically, another instance of the shared loop, decide, retrieve, synthesize, cite by span, drawing on Google Search as its grounding source. The practical consequence is consistent with the Google section: being retrievable in Google Search is the precondition for being cited when Gemini grounds there. As with the other surfaces, Google documents the loop and the citation structure but not how candidates are scored to decide which retrieved source becomes a citation.
Perplexity: the citation-first surface
What the documentation supports. Perplexity's own developer documentation describes it as a grounded answer engine that pairs a language model with real-time web retrieval and returns answers with source citations. Its API documents source-control filters directly: a domain filter that restricts or excludes specific domains (allowlist or denylist, up to twenty domains per request), and recency and date filters that limit results by time period or publication date. Two things are documented and worth stating plainly: retrieval is real-time rather than answered from training memory, and citation is integral to the product rather than an optional feature. This corroborates the shared retrieve-filter-generate-cite loop from another independent system, which is the useful point: the major systems converge on the same skeleton.
Where the documentation stops, and this report stops with it. Much has been written about how Perplexity ranks and selects among candidate sources, multi-layer rerankers, hybrid keyword-and-semantic retrieval, the share of citations that overlap with Google's top results, the ratio of pages visited to pages cited. None of that is published by Perplexity. It comes from independent teardowns and third-party analysis, which may be informative but does not meet this report's standard for a stated fact about how the system works. So Perplexity is included here for what its own documentation confirms, the real-time, citation-first loop, and its internal scoring is treated as undocumented, exactly as it is for the other three.
The shared silence
Every one of these systems documents the shared skeleton and stops at the same place. None publishes how retrieved candidates are scored against each other, or how the system chooses which consulted source earns the visible citation. Google describes fan-out, the index gate, and passage selection but not the ranking function inside the AI answer. OpenAI documents the modes, the source/citation split, and the annotation format but not the relevance score. Anthropic documents that filtering keeps "relevant" content but not how relevance is judged. Perplexity documents the real-time, citation-first loop but not its reranking. Gemini documents its grounding loop and span-level citation metadata but not how grounded candidates are scored. The silence is industry-wide, not particular to one vendor.
Interpretation This is why the levers are framed as mechanism-justified direction rather than guaranteed cause, and why magnitude lives only in first-party measurement. The surfaces tell you the shape of the game and the gate to each arena. They do not tell you the referee's scoring, and no honest report can pretend otherwise. The optimization implication is not three separate playbooks but one asset engineered for the shared skeleton, with awareness of each surface's distinct gate: Google's index for its search surfaces and for Gemini grounding, Bing's index for ChatGPT enterprise, and clean self-contained passages for the span-binding systems, which is now most of them.
The gate
The Gate Before Retrieval: Entity Recognition
Why this comes before retrieval
The earlier sections treated the system as if it begins when a query arrives. It does not. Before any retrieval happens, the model already holds knowledge from training, and that prior knowledge shapes two things that decide your fate downstream: how the model forms its search queries, and whether it recognizes your brand as a coherent entity at all. This is the gate. A brand the model misunderstands before it searches is a brand that gets searched for badly and grounded inaccurately, no matter how clean the content it eventually retrieves.
What the vendors document about prior knowledge
All three providers document, in plain terms, that their models carry knowledge from training that is distinct from what they retrieve at query time, and that retrieval exists precisely to supplement it. Anthropic frames the web search tool as giving Claude access to information "beyond its knowledge cutoff," and documents that Claude decides whether to search at all based on the prompt: it searches when a request depends on information that is current, changing, or outside its training data, and answers directly from prior knowledge for established facts. OpenAI documents the same split structurally. Google documents the inverse relationship from the index side: RAG exists to improve the freshness and accuracy of responses by grounding them in retrieved pages, which is an implicit acknowledgment that ungrounded model knowledge can be stale or wrong.
Interpretation Two consequences follow. First, prior knowledge is a filter on retrieval, not just a fallback. If the model believes it already knows what your brand is, it may not search, or it may search using the framing it already holds. Second, that prior framing is the thing you cannot directly edit, because you cannot reach into training data. You can only influence it indirectly, through what the model retrieves and through how consistently the open web describes you. That makes entity clarity a long-game lever, not a quick fix.
The entity-recognition problem
The sharpest version of the gate is entity recognition: does the system correctly understand what your brand is, what category it belongs to, and what it should not be confused with. This is not exotic. It is the difference between a system treating a brand name as a company versus a person, or treating an ambiguous product name as the more famous thing that shares its spelling. When the system's entity model is wrong, every downstream step inherits the error: query formation goes sideways, retrieval pulls the wrong neighborhood of content, and the grounded answer describes the wrong thing confidently.
Google's documentation gives one relevant, usable hook here. In its myth-busting guidance, Google tells site owners that its systems can understand synonyms and general meanings, so you do not need to capture every keyword variation. That is Google asserting strong entity and meaning resolution on its end. Interpretation the flip side of that confidence is that when the system's entity resolution is wrong, the same machinery that usually helps will now confidently retrieve and generate around the wrong entity, and it will do so without the exact-match keyword signals that once let you force disambiguation. Strong meaning resolution is a tailwind when the entity is clear and a headwind when it is not.
Worked example: a brand-classification problem
Field observation · practitioner work, not vendor documentation
For a residential property-maintenance brand whose name collides with a common personal name, a natural-language entity processor was observed classifying the brand as a person rather than as a business. The practical fix applied was consistent co-occurrence: pairing the brand name with disambiguating category context (for example, the brand name beside "property maintenance") across content, so the surrounding text repeatedly signals the correct category and the correct entity neighborhood.
Interpretation, tied to documented mechanism. Why would that fix work, mechanically? As the retrieval section established, retrieval operates on passages and the relevant span is isolated before generation. If the brand token appears repeatedly inside passages that also state its category and domain, then any passage retrieved about the brand carries its disambiguating context with it, and the span the system lifts is self-disambiguating. The co-occurrence fix is, in effect, passage-level entity engineering: it does not argue with the model's prior, it floods the retrievable layer with consistent, correctly categorized context so that what gets retrieved and grounded points to the right entity. This connects the gate directly to two levers that follow, self-contained passages and authentic third-party presence.
The honest limit. This is one observed case with one applied fix. It is consistent with the documented mechanism, but it should be read as a worked illustration of the principle, not as a proven, generalizable formula with a known success rate. Moving it from illustration to evidence would require before-and-after measurement of entity resolution and description accuracy, which is named in the closing agenda.
The accuracy dimension: what the model says about you
Entity recognition is upstream of a second problem: factual accuracy of how the brand is described. A correctly identified entity can still be described with stale or wrong attributes, because the model's prior knowledge and the retrieved content can disagree. The retrieval mechanism is what makes this fixable in principle. Google's RAG exists to improve freshness and accuracy by grounding in current pages; Anthropic's search results carry a page_age field; OpenAI's search exists to supplement training knowledge with current information. Interpretation where the open web carries clear, current, consistent statements of the truth about a brand, grounding has correct material to retrieve and the answer improves. Where the web is silent, contradictory, or stale on a given fact, the model falls back toward its prior, which is exactly where inaccuracies originate. The lever is to make the correct, current statement of each important fact easy to retrieve and hard to miss, in self-contained form, across sources the systems actually consult.
Interpretation This is why the GEO and accuracy tracking later matters at the entity level, not just the citation level. The question is not only "are we cited," but "when we are described, is the description correct." A brand can be cited accurately, cited inaccurately, or described inaccurately without citation, and only the first is a win.
Levers
The Levers
Each lever below follows the same discipline: the documented mechanism it rests on, the lever that follows, the outcome it serves, and the boundary past which only your own data can speak. They are organized by the mechanism they exploit rather than by which of the three letters they serve, because most serve more than one.
Cover the sub-questions, not just the headline
Win the index first, because it is the gate
Write self-contained passages, because the passage is the unit
Make claims span-liftable
Earn authentic third-party presence, not manufactured mentions
Treat freshness as a real signal where it is documented
Be a non-commodity source
The differentiated-surface point
Google draws a distinction the report should carry: AI Overviews are designed to appear only where they add benefit beyond classic Search and often do not trigger, while AI Mode is built for queries needing exploration, reasoning, or complex comparison that previously took multiple searches.
Interpretation The two Google surfaces reward different content shapes. A concise, cleanly stated answer is well-suited to the quick-gist job of an Overview; a thorough, well-structured treatment that supports comparison and follow-up is better matched to AI Mode's exploratory job. This is a reason to build content that does both: a clear answer up front, depth beneath it. It also means "did we appear in AI search" is the wrong question; "which surface, for which query type" is the right one.
What Google says you can stop doing for AI search
A short, high-value section, because it saves clients money and is fully documented. For Google's surface specifically, Google states these are unnecessary: llms.txt and other special machine-readable files or markup; breaking content into tiny pieces ("chunking"); rewriting content specifically for AI systems; and adding special schema.org markup for AI (structured data is not required for AI features, though Google still recommends it for rich results in classic Search).
Interpretation This applies to Google's surface, which runs on its existing index. It does not automatically generalize to ChatGPT or Claude, which retrieve differently. The passage-level discipline in Levers 3 and 4 is not the same thing as the "chunking" Google dismisses: Google rejects mechanically fragmenting a page, while the levers call for clarity and self-containment of individual claims within a normal page. Both can be true at once, which is exactly why the cross-vendor picture matters and why single-surface advice misleads.
A separate question: llms.txt
It is worth treating llms.txt precisely, because two different questions get collapsed into one.
For appearing in AI search answers. Google states directly that you do not need llms.txt for its generative AI features, grouping it with the other unnecessary tactics above. No major provider has confirmed using llms.txt to select or cite sources during web retrieval, and a signal the site owner fully controls is weak evidence to a system making its own relevance judgments. As a search-visibility lever it is unsupported. There is also no evidence that any provider reads your llms.txt at answer time to decide citations, so do not build it expecting AI-search citations.
For developer and agent tooling. Here the file has a real, documented use, though a narrower one than is often claimed. In its engineering guidance on writing tools for agents, Anthropic notes that when building tools with Claude it helps to give the model documentation for the libraries and APIs involved, and that LLM-friendly documentation is commonly found in flat llms.txt files on official documentation sites; Anthropic maintains one for its own API documentation. OpenAI likewise maintains llms.txt files for its Agents SDK documentation. So the established fact is first-party: the vendors publish and maintain llms.txt for their own developer docs.
Interpretation The honest reading: llms.txt is a convention for feeding clean documentation to models during development, with genuine first-party uptake in the developer-tooling context. It is not a search-visibility tactic, and treating it as one is the common mistake. For a documentation-heavy, API, or developer property where models consuming your docs is a real use case, it is a low-cost step worth taking. For everyone else it is optional, and it should never substitute for the seven levers above, which are what actually drive visibility. The accurate scope of the earlier "drop llms.txt" guidance is therefore: drop it as a search lever, consider it where developer-doc consumption by models genuinely matters.
Where the levers stop and data begins
Every lever above follows from documented mechanism. None of them tells you how much. The vendors do not publish how candidates are scored or which consulted source becomes the cited one, so any claim of the form "doing X raises citations by Y" cannot be carried by mechanism. It can only be carried by measurement. The honest version of this report says: here is what the mechanism entails you should do, and first-party measurement is what shows, for a given brand, the magnitude and the priority order. Until those figures are in for a specific case, the levers stand as mechanism-justified direction, not quantified promises, and a credible report says exactly that.
Measurement
Measuring It Honestly
The measurement problem, stated honestly
The levers above follow from documented mechanism. None of them tells you how much, because no vendor publishes its scoring function. So measurement is not a reporting afterthought here; it is the only admissible source of magnitude. Everything quantitative in this report lives in this part or it does not get said. Measurement also has to respect the three-outcome split, because each outcome is observed differently. Retrievability and ranking (SEO) are measured one way, citation (AEO) another, and answer-influence (GEO) a third, and conflating them produces the inflated, meaningless dashboards this report exists to replace.
Measuring SEO: the index and ranking layer
This layer is the most mature and the best instrumented, and it remains the precondition for the other two. What is documented for classic Search: Google states that sites appearing in its AI features are included in the overall Search Console performance report, where it continues to be tracked alongside everything else. Google also notes elsewhere that when people click through from results pages containing AI Overviews, it considers these clicks higher quality, meaning users are more likely to spend more time on the site. That click-quality statement is Google's own assertion and is represented here as such, not as independently verified fact.
What changed on June 3, 2026: Google launched a dedicated Search Generative AI performance report in Search Console, a separate view of a site's visibility inside generative AI features. In Google's own words, it gives dedicated views of impressions within generative AI features on Search, such as AI Overviews and AI Mode, as well as generative AI features in Discover, while that same data continues to feed the overall performance report. Google defines the core metric as impressions: how often URLs from your site appeared in generative AI features in Search and Discover. The report breaks impressions down by pages, countries, devices (for Search results), and dates, with hourly, daily, weekly, and monthly granularity. Google states it is rolling this out to a subset of websites to test and gather feedback before making it widely available, and that it may add additional metrics over time. (Authors: Hillel Maoz and Moshe Samet, Google Search Central blog, June 3, 2026.)
Two precision notes that respect the limits of what Google actually said:
- Google's post describes the rollout only as "a subset of websites." It does not name a country. Multiple secondary reports state the rollout is UK-first, driven by the UK CMA's requirements under the Digital Markets, Competition and Consumers Act 2024; that is plausible and consistent but is not stated in Google's post, so it is reported here as secondary, not as Google's word.
- Google lists impressions as the metric shown and says more metrics may come. It does not explicitly frame the report as "impressions only, no clicks or position." Reading it that way is a reasonable inference from what is listed, but it is an inference, not a Google statement.
Interpretation The dedicated report is a genuine upgrade: for the first time there is a first-party Google surface isolating AI-feature impressions, filterable by country and device. But the caution actually tightens rather than loosens. Google itself commits only to impressions and explicitly leaves richer metrics (clicks, CTR, position) as future work, so do not promise clients an "AI Overviews traffic and click-through" picture the tool does not yet provide. Treat the dedicated report as the source of truth for AI-feature impression visibility, and the overall report plus a ranking and backlink tool for indexability, position, and engagement.
Measuring AEO: citation, done with metric discipline
This is where most "AI visibility" reporting goes wrong, by counting the wrong thing and inflating it. The discipline this report adopts: measure unique citation coverage, the count of distinct prompts or queries for which the brand is cited, not raw citation volume. Raw citation counts inflate heavily because a single piece of content can be cited many times across near-identical prompts, so a raw count rewards redundancy and obscures whether coverage is actually broad. The correct denominator is prompts, not citations.
On a per-page basis, raw citation count overstated unique prompt coverage by roughly a hundredfold in this window. The best-distributed owned page appeared across 99 distinct prompts yet logged 9,929 raw citations. Another top page: 97 distinct prompts against 12,955 raw citations. Reporting "12,955 citations" as a visibility figure would be meaningless inflation; the honest coverage number is 97 of the prompt set.
First-party AEO data, anonymized B2B SaaS brand kit · 28-day window, May to June 2026The exact multiple is window-dependent and should be recomputed each period, not treated as a fixed constant, but the direction is stable and large: always report prompts-based coverage, never raw citation volume.
What to track at this layer: unique citation coverage by topic cluster; citation rate (share of relevant prompts in a category where the brand is cited); concentration (how many pages account for what share of citations, a risk signal when too few pages carry the load); and citation stability over time, because citations rotate.
A worked contrast on concentration, from real data. The same B2B SaaS brand kit above showed a broad owned footprint: across the reporting window its owned domain was cited from 398 distinct URLs, holding roughly 13 percent citation share against a nearest competitor near 2.7 percent, with the top pages clustered tightly in prompt coverage (99, 97, 94, 94, 91 prompts across the top five). That is a healthy distribution: no single page carries the brand.
The risk case is the inverse, where a handful of pages account for most citations, so that losing or staling one collapses coverage. Concentration is therefore a managed metric, not a vanity one: track what share of citations the top pages carry, and treat rising concentration as fragility.
Interpretation Concentration deserves explicit tracking because it is a documented-mechanism risk, not a vanity metric. If retrieval and citation are selective and span-bound, as established earlier, then a brand whose citations cluster into a tiny number of pages is fragile: lose or stale one of those pages and coverage collapses. Tracking concentration turns a hidden dependency into a managed one.
Measuring GEO: answer influence beyond the citation
This is the widest and least mature layer, and the retrieval mechanism established earlier is what makes it measurable in principle. What is documented: OpenAI exposes a sources field that returns the complete list of URLs the model consulted, distinct from the inline citations that show only the most relevant references, and states the number of sources is often greater than the number of citations. That gap is the GEO measurement surface: presence in the consulted set without a visible citation is real influence that citation-only tracking misses.
Interpretation Where the tooling exposes consulted sources, GEO can be measured as share of the consulted set, not just the cited set. Where it does not, GEO is approximated through share-of-voice style sampling: run a representative prompt set across surfaces and measure how often the brand appears or is described in the generated answer, cited or not. This is sampling, not census, so it is reported as a directional indicator with its sampling method stated, never as a precise count.
A real, surface-scoped example of trend tracking. For a property-maintenance brand, the Bing Webmaster Tools AI Performance export for March 7 to June 3, 2026 showed citations on the Bing and Copilot surface growing from roughly 30 per day in the first half of the window to roughly 97 per day in the second, while the number of distinct pages cited per day rose alongside it from about 8 to about 12. Two things make this a usable GEO signal: it is first-party from the surface's own dashboard, and it shows footprint both growing and broadening rather than concentrating.
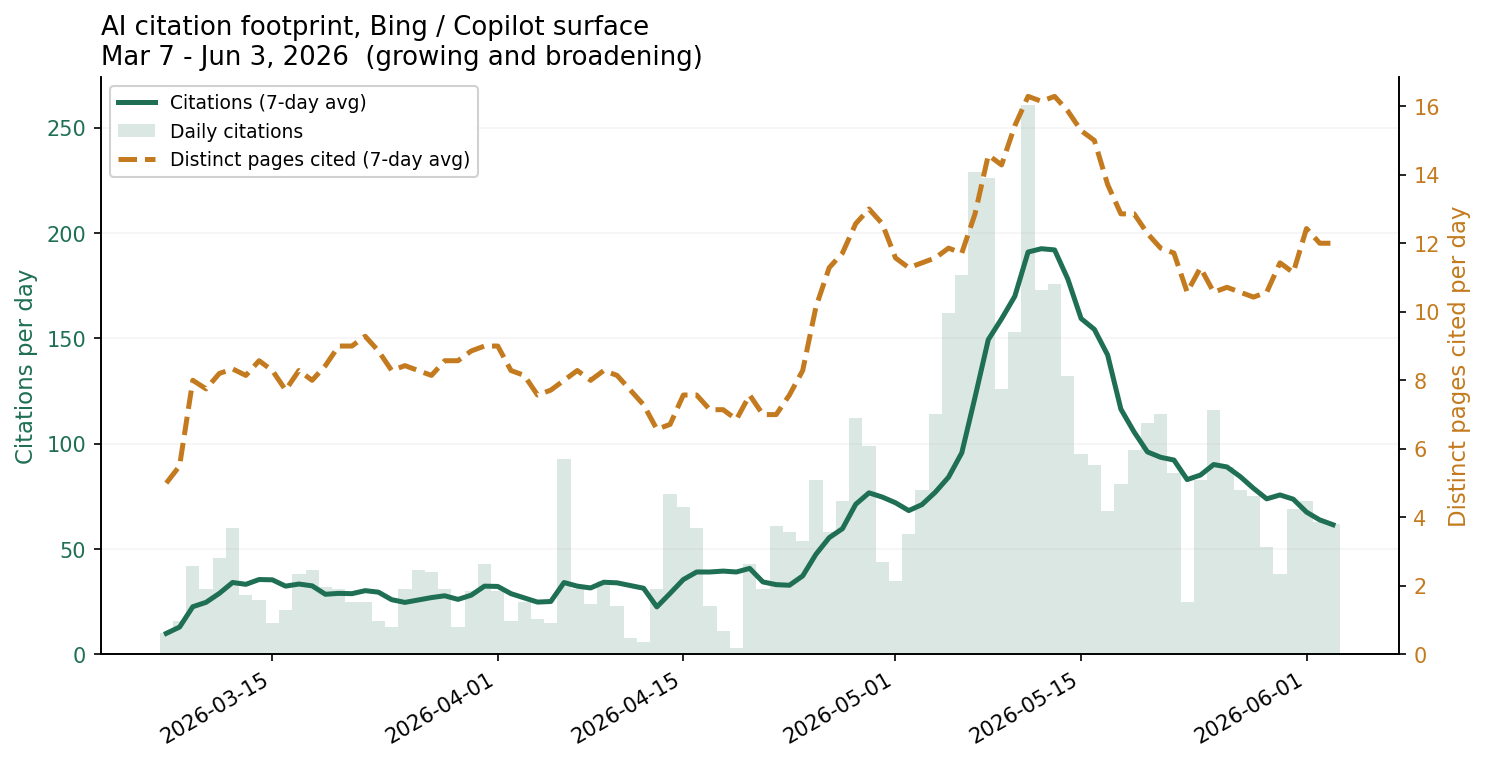
The honest scope: this is one surface only (Bing and Copilot), and the export is a daily rollup of total citations and distinct-pages-cited, so it supports a breadth-and-trend reading but not a per-page concentration breakdown. Different surfaces require their own instrumentation; there is no single cross-engine citation feed.
The volatility problem
A measurement design point that follows directly from the retrieval mechanism. Citations and surfaced sources rotate; an answer's cited set today is not guaranteed to be its cited set next week. The vendors' own framing supports this: Google states AI Overviews often do not trigger at all and vary by model and technique, and the retrieval-and-filter loop is re-run per query rather than served from a fixed ranking.
Interpretation This makes one-time audits actively misleading. A single snapshot of "we are cited for these prompts" can swing materially on a re-run. The reporting cadence has to be continuous or at least repeated on a fixed schedule against a fixed prompt set, so the signal is the trend and the stability, not a single reading. Report ranges and trends, not point-in-time hero numbers.
What a defensible report contains
- The precondition layer (SEO): indexation, impressions, position, click quality, technical health, from Search Console and a ranking tool, with no overclaim of isolated AI-feature traffic.
- The citation layer (AEO): unique citation coverage and citation rate by cluster, concentration as a managed risk, and stability over time, using the prompts-based metric and never raw citation counts.
- The influence layer (GEO): mention share and consulted-set presence against a fixed prompt set, reported as sampled and directional.
Each metric is tied to a mechanism and a lever established earlier, so the report reads as a causal chain rather than a dashboard: this is what the system does, this is what we therefore changed, this is what moved, and this is how confident we are in the magnitude.
Agenda
What to Measure Next
A few questions in this report can only be answered by instrumentation specific to a given brand. They are named here as the agenda that turns this framework into proof.
Establish the baseline
Pull the dedicated Google generative-AI impressions report once the property has access, alongside ranking and indexation data, so AI-feature visibility has a starting line rather than a one-time snapshot.
Quantify the levers
Mechanism justifies direction; only first-party measurement justifies magnitude. Tracking prompts-based citation coverage before and after specific changes, by cluster, is what converts "this should help" into "this moved coverage by this much for this brand."
Prove the entity fix
Where a brand suffers misclassification or inaccurate description, a before-and-after measurement of entity resolution and description accuracy, against a fixed set of facts, is what turns the entity-clarity argument from a sound principle into demonstrated results.
Audit accuracy, not just citation
Because a brand can be described inaccurately without ever being cited, a periodic audit of how each surface describes the brand, against a fixed fact set, measures the outcome that citation tracking alone misses.
Instrument each surface
There is no single cross-engine citation feed. A complete picture requires the relevant first-party dashboard for each surface that offers one, read for what it actually reports and scoped accordingly, rather than one number claimed to cover them all.
Summary
In Short
Generative search expands the query, retrieves against an index or a scoped source set, filters to the relevant passage, generates an answer, and binds each citation to a short span. That shape is documented by all three major providers; the scoring inside it is not. AEO and GEO are therefore not a separate craft from SEO, but they are not identical to it either. They are additional outcomes, being cited and being influential, layered on the precondition of being retrievable.
The work that earns them is mostly the work that has always earned good search visibility: original content, sound technical foundations, clear writing, with two new disciplines on top. First, writing self-contained passages that survive being lifted out of context. Second, measuring the right things, prompts-based coverage and accuracy rather than inflated citation counts, continuously rather than once.
Want this discipline applied to your brand?
PropSaaS Growth builds SEO, AEO, and GEO systems for PropTech, FinTech, and B2B SaaS, with every recommendation tied to documented mechanism and every magnitude claim tied to first-party measurement.
Book a discovery call →Appendix
Sources
This report draws its factual claims from primary documentation published by the companies that build these systems, read in full. Figures come from live measurement. The distinction between documented fact and reasoned interpretation is carried throughout the text.
Primary vendor documentation
- Google Search Central, "Optimizing your website for generative AI features on Google Search." Source for retrieval-augmented generation and query fan-out, including the worked fan-out example; the position that optimizing for generative search is still SEO; the emphasis on original, non-commodity content as the highest-impact factor; and the guidance on which tactics are unnecessary and on authentic versus inauthentic mentions.
- Google Search Central, "AI Features and Your Website." Source for the index-and-snippet eligibility gate, the distinction between AI Overviews and AI Mode, the fan-out description, and the controls available to site owners.
- Google Search Central Blog, "Introducing Search Generative AI performance reports in Search Console" (June 3, 2026), with Google's Search Console help documentation for the generative-AI performance report. Source for the dedicated report, the impressions metric, and the page, country, device, and date breakdowns. The absence of click data was confirmed by a Google spokesperson via trade press. The United Kingdom rollout sequence is reported by trade press and attributed to UK Competition and Markets Authority requirements; it is not stated in Google's own documentation, which describes the rollout only as a subset of websites.
- OpenAI, "Web search" (API documentation). Source for the three search modes, the query-to-answer flow, the citation annotation format with character indices, the Bing substrate for enterprise web results, and the documented distinction between sources consulted and sources cited.
- OpenAI Agents SDK documentation. Source for the maintained llms.txt file for developer documentation.
- Anthropic, "Web search tool" (Claude platform documentation). Source for the search-and-cite loop and its repetition within a request, dynamic filtering and its rationale, the citation structure including the 150-character cited-text limit, and the page-age field.
- Anthropic, "Writing effective tools for agents" (engineering blog, September 11, 2025). Source for the use of llms.txt as an LLM-friendly documentation format when building tools, and for Anthropic maintaining one for its own API documentation.
- Google, Gemini API documentation, "Grounding with Google Search" (ai.google.dev), with the GroundingMetadata reference in the Google Cloud and Vertex AI documentation (cloud.google.com). Source for how Gemini grounds answers in Google Search, the decide-then-search loop, and the grounding metadata (groundingChunks and groundingSupports) that binds text segments, by start and end index, to web sources. All Gemini claims are drawn from Google-owned documentation only.
- Perplexity, developer documentation (docs.perplexity.ai). Source for Perplexity operating as a grounded, citation-first answer engine with real-time retrieval, and for its documented source-control filters (domain allowlist/denylist up to twenty domains, plus recency and publication-date filters). Perplexity does not publish its source-ranking or reranking mechanics; claims about those circulate only in third-party analysis and are not relied on here.
Measurement data
- Citation-tracking data for one B2B SaaS brand, drawn live from its AEO tracking platform for a 28-day window. Source for the prompts-versus-raw-citations comparison and the citation-distribution figures. Specific pages and competitors are withheld; only aggregate figures are used.
- Bing Webmaster Tools AI Performance export for one brand, a daily series across a roughly three-month window. Source for the citation-growth trend on the Bing and Copilot surface (Figure 1). Scope is that surface only, and the export is a daily rollup rather than a per-page breakdown.
On excluded sources
Consistent with its method, this report does not rely on SEO and marketing blogs, third-party teardowns, or citation-overlap studies for any factual claim about how the systems work. Where such material was encountered it was treated as commentary, not fact.

Gemma Smith
Founder of PropSaaS Growth. Ten-plus years in PropTech, now building organic, AEO, and AI-search visibility systems for vertical B2B SaaS. This report is part of an ongoing effort to keep AI-search advice tied to what the vendors actually document.